一、Pod监控相关指标
对于Pod内存相关的指标,主要有两个数据源:
- 基于kube-state-metrics,采集到的是内存Limits和Requests的设置情况。关键的指标如下:
| 指标 |
含义 |
| kube_pod_container_resource_limits_memory_bytes |
Pod内存Limits设置量 |
| kube_pod_container_resource_requests_memory_bytes |
Pod内存Requests设置量 |
- 基于kubelet上的CAdvisor,采集到的是内存使用情况。关键的指标如下:
CAdvisor是Google开源用于收集容器资源和性能指标的一个工具,对于Kubernetes,其集成在kubelet里面,可以收集到每个节点上的Pod指标。
| 指标 |
含义 |
| container_memory_usage_bytes |
当前使用的内存总量。包括所有使用的内存,不管有没有被访问 (包括 cache, rss, swap等)。 |
| container_memory_rss |
RSS使用量。RSS是常驻内存集(Resident Set Size)的缩写,是分配给进程使用实际物理内存,包括所有分配到的栈内存和堆内存 以及 加载到物理内存中的共享库占用的内存空间。不包含磁盘缓存 |
| container_memory_cache |
缓存使用量。 |
| container_memory_swap |
虚拟内存使用量。虚拟内存(swap)指的是用磁盘来模拟内存使用。对性能有影响,一般不用。 |
| container_memory_working_set_bytes |
当前内存工作集(working set)使用量。工作区内存使用量=活跃的匿名与和缓存,以及file-baked页。(working_set <= usage) |
| container_memory_failcnt |
申请内存失败次数。 |
| container_memory_failures_total |
内存申请错误总次数。 |
基于以上的指标,就可以计算Pod的内存使用率,当然,需要Pod有设置Limits才有意义
1
| sum(container_memory_working_set_bytes{pod!="POD", container!=""}) by (pod) / sum(kube_pod_container_resource_requests_memory_bytes{}) by (pod)
|
二、关于Pod OOM
先说结论,Pod OOM主要看的是working_set的使用量是否超过limits。
准备一个简单的程序,其功能是不断地申请内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
package main
import (
"fmt"
"net/http"
"time"
"os"
"strconv"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
ticker, err := strconv.ParseInt(os.Getenv("Ticker"), 10, 64)
if err != nil {
panic(err)
}
memoryTicker := time.NewTicker(time.Millisecond * time.Duration(ticker))
leak := make(map[int][]byte)
i := 0
go func() {
for range memoryTicker.C {
leak[i] = make([]byte, 1024)
i++
}
}()
http.Handle("/metrics", promhttp.Handler())
fmt.Println("Strat listening on 0:8000...")
http.ListenAndServe(":8000", nil)
}
|
1
2
3
4
5
6
|
FROM golang:alpine3.15
WORKDIR /app
COPY main ./
EXPOSE 8000
CMD ["./main"]
|
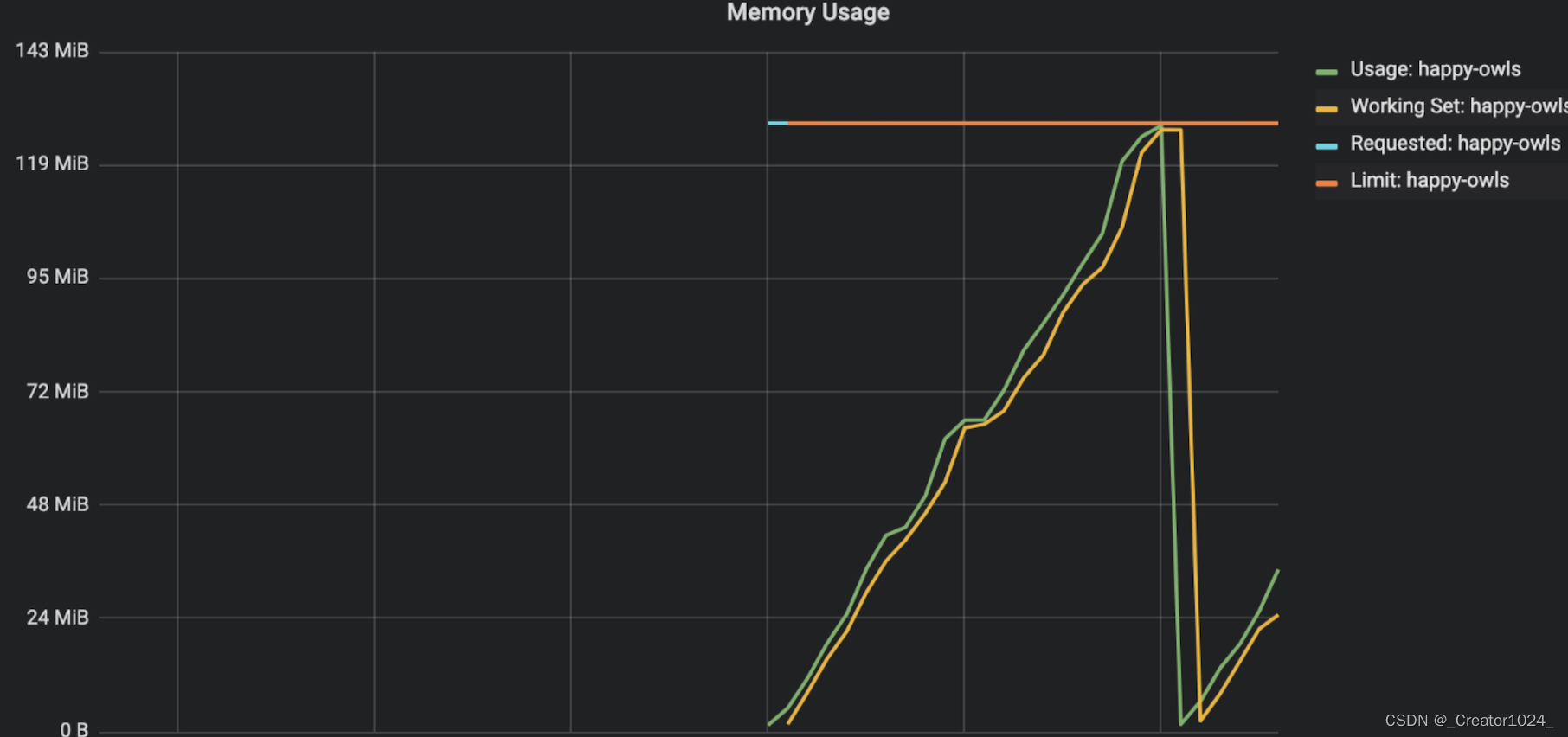
WorkingSet(container_memory_working_set_bytes)和Usage(container_memory_usage_bytes)基本上是以1:1的趋势到达limits,然后Pod触发OOM
接下来在程序中添加一个goroutine,不断在文件系统上写入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
package main
import (
"fmt"
"net/http"
"time"
"os"
"strconv"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
ticker, err := strconv.ParseInt(os.Getenv("Ticker"), 10, 64)
if err != nil {
panic(err)
}
memoryTicker := time.NewTicker(time.Millisecond * time.Duration(ticker))
leak := make(map[int][]byte)
i := 0
go func() {
for range memoryTicker.C {
leak[i] = make([]byte, 1024)
i++
}
}()
fileTicker := time.NewTicker(time.Millisecond * time.Duration(ticker))
go func() {
os.Create("/tmp/file")
buffer := make([]byte, 1024)
defer f.Close()
for range fileTicker.C {
f.Write(buffer)
f.Sync()
}
}()
http.Handle("/metrics", promhttp.Handler())
fmt.Println("Strat listening on 0:8000...")
http.ListenAndServe(":8000", nil)
}
|
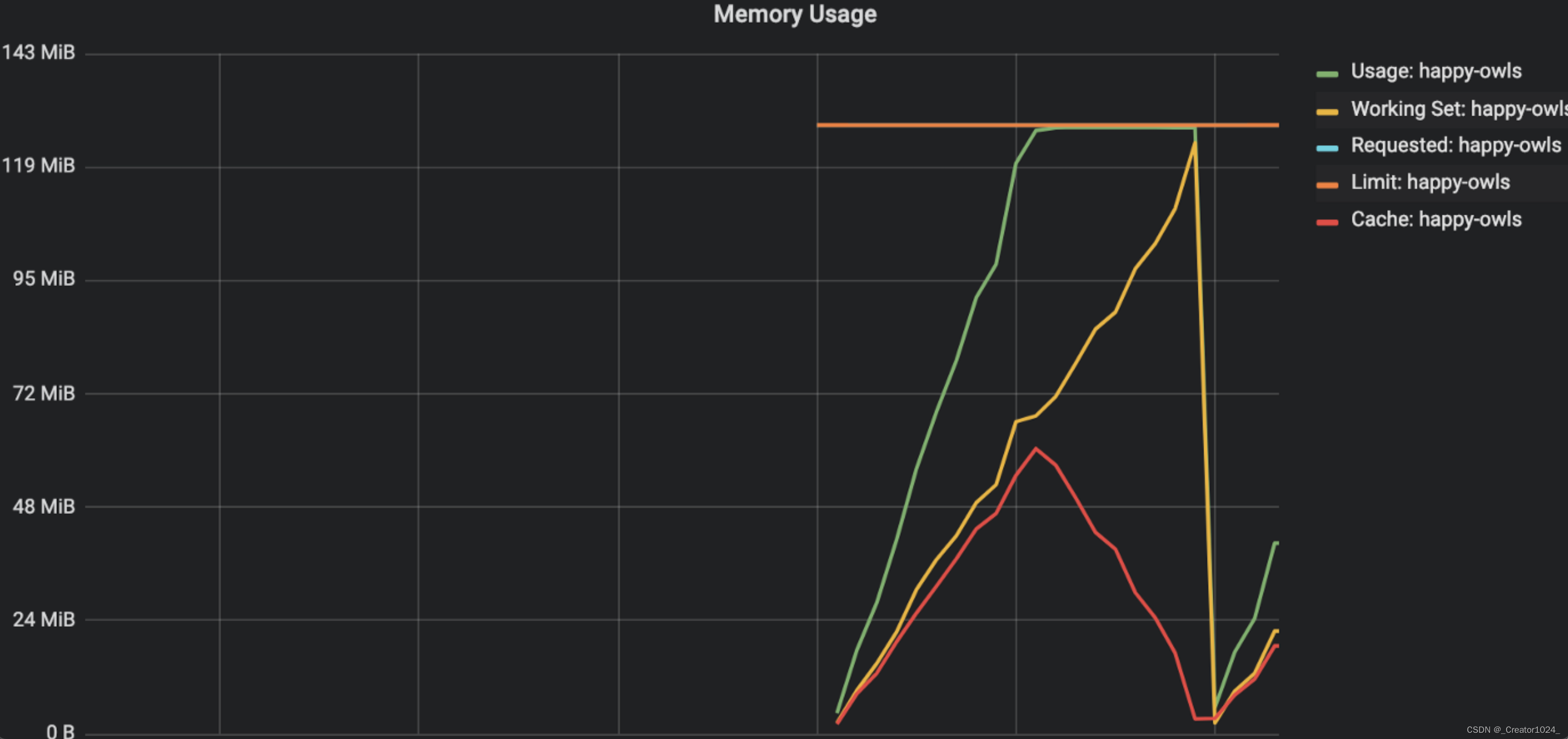
当Usage达到Limits,Pod不会OOM,随着WorkingSet继续增大,Cache逐渐减小,等WorkingSet到达Limit,Pod才OOM。
说明Usage中包含文件系统页面的缓存。当实际内存不够用的时候,这些缓存会让给程序使用。因为仅仅为了缓存就把程序给OOM掉是不合理的。